
Route AI workloads by data-sensitivity tier — the core of an investment firm's Claude deployment decision.
An investment analyst is finishing a memo at 11pm. She has a draft thesis on a listed company her investment firm is quietly accumulating — positions, valuation, the catalyst nobody else has spotted yet. She pastes it into Claude to tighten the argument.
Where does that text go? Which country does it sit in? Could it ever surface in a model's training data, or in another tenant's session? For most businesses these are abstract questions. For an investment firm, they are the whole question — because what she just pasted is exactly the kind of market-sensitive, potentially material non-public information that confidentiality rules, information barriers, and securities regulators exist to protect.
We recently advised a Malaysia-based investment institution through precisely this decision. They had 100+ knowledge workers, an existing Microsoft 365 footprint, and a clear mandate: adopt Claude across the investment team without creating a confidentiality or residency exposure. The interesting finding wasn't which model — the models are identical across every channel. It was that the right answer is not one deployment. It's a deployment chosen per data-sensitivity tier. This article is that framework, generalised so any investment or asset-management firm can apply it.
The sensitive asset is information, not personal data
Most AI governance conversations start with personal data — names, IC numbers, customer records, PDPA obligations. That lens matters, but for an investment desk it's secondary. The data at stake is investment theses, live positions, strategic asset allocation, deal pipelines, and insider / MNPI that staff may hold as part-owners of listed companies.
That changes which risks dominate. The decision is driven by confidentiality, data residency, and information-barrier controls — above the usual personal-data checklist. A model that's perfectly acceptable for drafting a recruitment email is not automatically acceptable for a memo describing an unannounced acquisition.
So the first move is not picking a vendor. It's classifying your data.
The data-sensitivity spectrum (the part most firms skip)
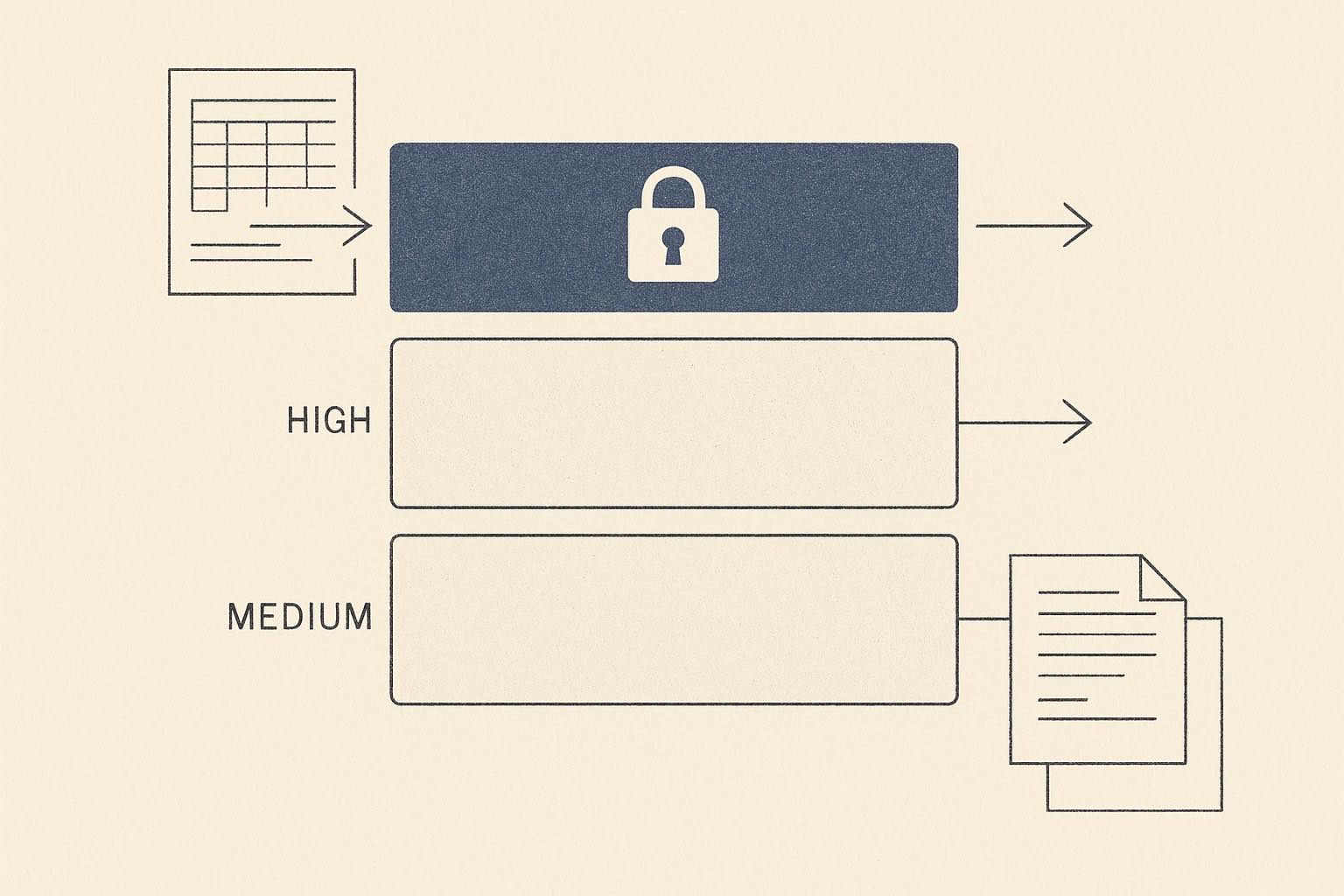
Every workflow your team wants to run through Claude sits somewhere on a spectrum. We found it useful to define three tiers explicitly:
- High sensitivity — investment theses, current positions, SAA, deal pipelines, anything touching insider / MNPI. If this trained a third-party model or persisted outside the firm's control, that's a serious incident. Requirements: no-training guarantees, zero data retention, hard tenant isolation, and ideally in-region — even in-country — processing.
- Medium sensitivity — internal research notes, meeting summaries, non-public-but-not-market-moving documents, policy drafts. You want isolation and no-training terms, but the residency bar is lower.
- Low sensitivity — summarising a public earnings call, polishing prose, drafting internal comms, answering "how do I use this template" questions. Convenience and feature richness matter more than residency here.
The mistake we see firms make is treating AI as a single binary decision — "is Claude approved or not?" — when the honest answer is "approved for these tiers via this path, and that tier via that path." Once you accept the spectrum, the deployment question almost answers itself.
The three ways to run Claude — and why they're not equal
The same Claude models — Opus 4.8, Sonnet 4.6, and Haiku 4.5 — are available through three channels. The model is identical. Everything around the model differs.
- Claude Enterprise — Anthropic's first-party product (the claude.ai application). You get the richest experience out of the box: Projects, web search, file creation, connectors to SharePoint and Drive, SSO via your identity provider. You operate nothing; you consume a finished product. The catch: data is stored in the United States, and the strongest geographic control available is a US-only inference setting — there is no Singapore or APAC residency option.
- Claude via AWS (Amazon Bedrock) — the model served as an API on AWS infrastructure. You build the application layer and call it from inside your own AWS account and VPC, with your own encryption keys, no training on your data, and data at rest in your account. The catch for our region: from Singapore and Malaysia, the latest Claude is served through a global endpoint that can route inference worldwide. Keeping processing contained to a specific region currently means routing through a foreign region such as Tokyo or Sydney — data still leaves Malaysia (AWS Bedrock cross-region inference).
- Claude via Google Cloud (Vertex AI) — architecturally the mirror of Bedrock: the model as an API on Google infrastructure, called from your own project with your own keys and no training. Its distinguishing feature is a Singapore regional endpoint (asia-southeast1) that keeps inference in-region, confirmed for Opus 4.8, Sonnet 4.6, and Haiku 4.5 (Claude models on Google Cloud Vertex AI).
A practical note we had to correct during the engagement: not every model carries the same context window. Opus 4.8 and Sonnet 4.6 offer a 1M-token context at standard pricing; Haiku 4.5 runs a smaller window. Worth checking against your actual document sizes before you assume "it'll all fit."
The uncomfortable finding: the ideal quadrant is empty
Plot the two axes an investment firm actually cares about — product richness on one, data-residency control on the other — and a clear gap appears. As of mid-2026:
- Claude Enterprise wins on features but stores data in the US.
- AWS in Singapore/Malaysia gives you account-level isolation and your own keys, but routes inference globally.
- Only Google Cloud's Vertex Singapore endpoint keeps data in-region — but you build the application yourself; there's no turnkey product.
In other words, no single option gives you both a finished product and in-region data today. Anyone who tells you otherwise hasn't read the regional fine print. (This is a fast-moving area — confirm the current residency posture of each channel before you commit; the shape of the trade-off is what matters, not any single month's snapshot.)
That emptiness is exactly why the data-sensitivity spectrum is the unlock. You don't need one deployment to be perfect for everything. You need each tier routed to the channel that fits it.
Six risks worth assessing before you sign anything
We structured the evaluation around six dimensions. They're a useful checklist for any firm:
- Confidentiality — no-training terms, zero data retention, tenant isolation. Your theses must never become someone else's model weights.
- MNPI and information barriers — data classification, segregated workspaces, and the equivalent of Chinese-wall controls so material non-public information can't leak across teams via a shared prompt history.
- Sovereignty — in-region, ideally in-country, inference and storage; customer-held encryption keys.
- Compliance — for Malaysian firms this means mapping the deployment against Bank Negara's Risk Management in Technology (RMiT) policy and the Personal Data Protection Act where incidental personal data is involved. Treat any regulatory reading as a starting point for your own counsel, not a substitute for it.
- Vendor and exit risk — a signed data-processing agreement, multi-model flexibility, and a credible portability path so you're not locked in.
- Model governance — human-in-the-loop on decisions, evaluation and guardrails, and alignment with any Shariah or ESG mandates your funds carry.
Cost is decided by structure, not by the rate card
A surprise for many finance teams: the per-token price is identical whether you call Claude through the first-party API, AWS, or Google Cloud — a point we break down in detail in Anthropic API vs Bedrock for Claude in Malaysia. As a reference, Sonnet 4.6 — the practical workhorse for most knowledge tasks — runs around USD 3 per million input tokens and USD 15 per million output tokens; Haiku 4.5 is roughly a third of that for high-volume triage; Opus 4.8 sits at the top for the hardest analysis (Anthropic's published pricing). Output tokens cost several times more than input, so verbose prompting is the silent cost driver.
Because the rate is fixed, cost is decided by structure:
- Claude Enterprise is a per-seat licence plus usage. All-in, expect a meaningful per-user monthly cost — but that premium buys the finished product and takes the operating burden off your team.
- AWS or Google Cloud look far cheaper on raw tokens, but that number excludes the application you must build and run — engineering, hosting, support — typically several person-weeks of build plus ongoing platform cost.
The real comparison isn't "seat price vs token price." It's "the product and zero operating burden" versus "lower running cost plus a build you own." Two levers cut the bill on any channel: prompt caching (cached input is dramatically cheaper on repeated context) and batch processing (around half price for non-interactive jobs). And one honest caveat we always make explicit — moving to a cloud-hosted stack reduces cost meaningfully, often by a large margin, but never to zero. Someone still runs and bills for the platform.
The recommendation: two tracks under one governance wrapper
For the investment institution we advised, the answer that fell out of the spectrum was a two-track deployment:
- High-sensitivity, market-moving work runs through the in-region, residency-controlled path — Google Cloud Vertex on the Singapore endpoint, inside the firm's own project, with customer-managed keys and no training. This is where theses, positions, and anything MNPI-adjacent live.
- Low-sensitivity, everyday work — drafting, summarising public material, internal Q&A — runs on Claude Enterprise (US), where the feature richness and zero operating burden genuinely improve productivity and the data simply doesn't warrant residency controls.
- One governance wrapper sits over both: a single data-classification policy, consistent access controls, and clear staff guidance on what goes where. The deployment is split; the governance is not.
If your residency requirements go further than any managed cloud can satisfy — data that must never leave infrastructure you control — a fully self-hosted private model is the next step up. We weigh that trade-off in Private LLM in Malaysia: Who Needs It and When It Makes Sense.
Layer model-tiering on top and the economics improve further: route high-volume triage and classification to Haiku 4.5, do the bulk of the analytical work on Sonnet 4.6, and reserve Opus 4.8 for the genuinely hard, long-horizon reasoning. You pay flagship rates only where flagship reasoning earns its keep.
What this means for your firm
If you're an investment or asset-management firm weighing Claude — or any frontier AI — the order of operations matters more than the vendor shortlist:
- Classify your workflows into sensitivity tiers before you evaluate a single product.
- Accept that no one deployment is perfect for all tiers today, and design for routing instead.
- Pin down residency, no-training, and isolation terms in writing — not from a sales deck, from the contract.
- Cost the build-and-run, not just the token rate.
- Wrap the whole thing in one governance policy your compliance team actually owns.
Get that framework right and the technology choices become straightforward. Get it wrong and you've either throttled a genuinely useful tool or created an exposure your regulator will eventually ask about.
References
- Anthropic — Claude pricing — current per-token rates and model lineup
- Amazon Bedrock — Cross-region inference — how Bedrock routes requests across regions
- Claude models on Google Cloud Vertex AI — regional endpoints and availability
- Bank Negara Malaysia — Risk Management in Technology (RMiT) policy
- Personal Data Protection Department Malaysia — PDPA and data-protection guidance
Konsultasi percuma
Deploying AI where data sensitivity is non-negotiable?
We help Malaysian investment firms, banks, and regulated businesses map their data-sensitivity tiers and architect a Claude deployment that holds up to compliance scrutiny — across Enterprise, AWS, and Google Cloud.
Explore our AI Solutions
Read: Anthropic API vs Bedrock for Malaysian businesses