Enterprise AI & private LLM
AI your board wants. Control your regulators require.
Your board is asking for AI. Your compliance team can't let company data anywhere near public cloud AI. We resolve that tension: enterprise AI deployed inside your firewall — your data never leaves your infrastructure.
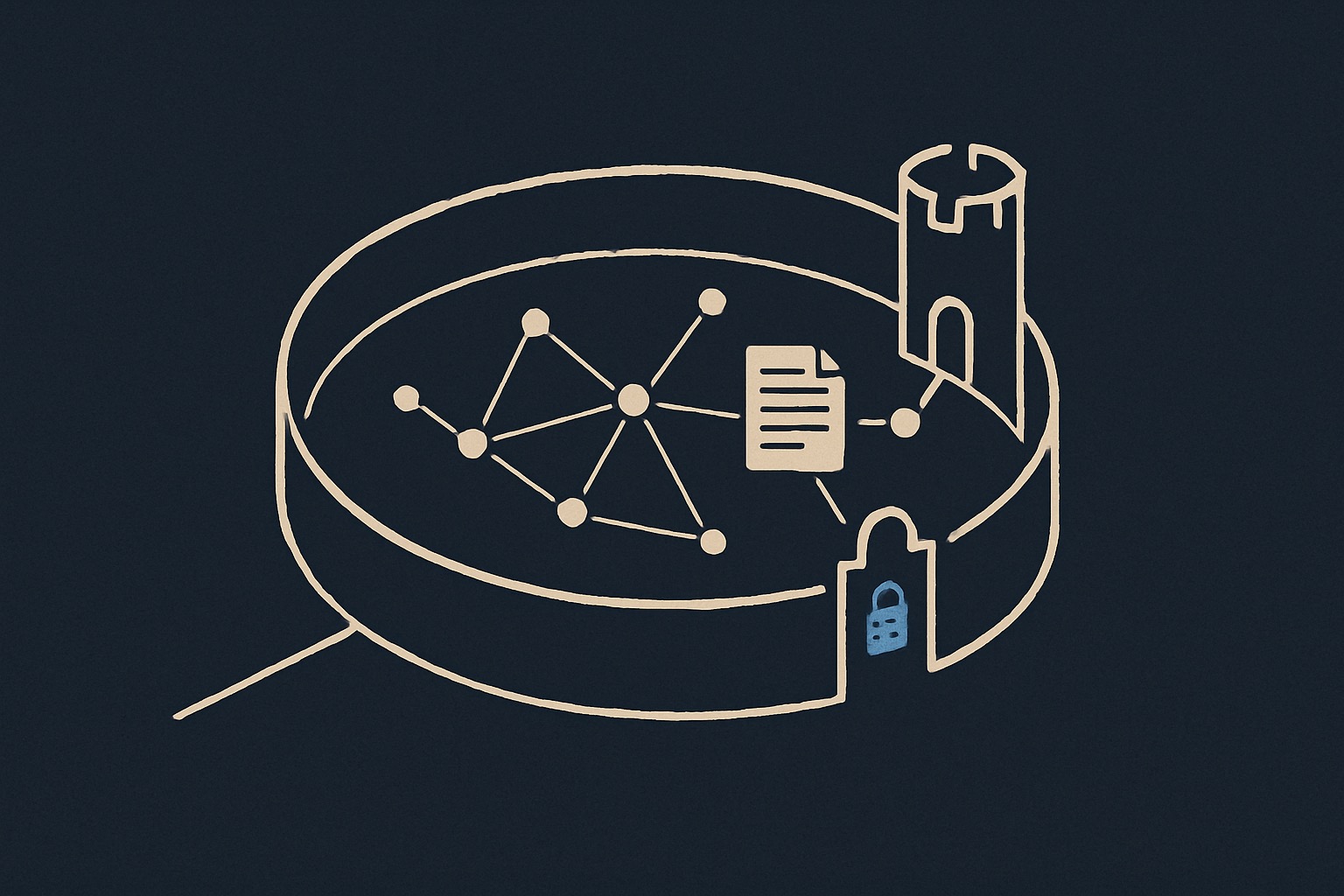
How private AI works
Two ways to run AI privately
There is no single right architecture — it depends on what your regulators, policies, and workloads demand. These are the two paths we build, and we help you choose between them.
Option A
A private LLM on your own servers
Open-weight models like Llama and Qwen, deployed inside your firewall on hardware you control. No external API calls, no per-token fees, and an air-gapped option for the strictest environments.
- Your data never leaves your network
- Runs on-premise or in your private cloud
- Full audit trail under your governance
Best when data sovereignty is non-negotiable.
Option B
Claude with enterprise controls
Frontier capability through the Claude Developer Platform and major cloud platforms — under enterprise agreements where your data is not used for model training by default. We build on Claude as a member of the Anthropic Claude Partner Network.
- Frontier reasoning for complex agentic work
- Enterprise agreements and data controls
- Available through major cloud platforms
Many clients run a hybrid — private models where data must stay, Claude where policy permits. We help you choose, then build both.
Flagship product
Business AI: your private enterprise assistant
A production enterprise assistant powered by a private LLM — deployed 100% on-premise, trained on your company data, and governed by your own access controls. Staff draft documents and query your knowledge base; nothing ever leaves your servers.
What's inside
- 100% on-premise deployment
- Private LLM trained on your company data
- Document generation and automation
- Knowledge base your staff can query
- Enterprise SSO and access control
What you get
Everything a private deployment needs to work
RAG on your own documents
Answers grounded in your policies, contracts, and manuals — with source citations, so staff trust what the assistant says.
Fine-tuning for your domain
Models adapted to your terminology, formats, and languages — including Bahasa Malaysia and Chinese — where retrieval alone is not enough.
Governance and access control
SSO integration, role-based permissions, and audit trails — so the right people see the right data and compliance can verify it.
Integration with existing systems
Connected to your ERP, CRM, and document stores through APIs — AI that works inside the systems your teams already use.
Infrastructure sized and supplied
GPU servers specified, procured, and installed through our hardware partners — one accountable team from sizing to go-live.
Local support after go-live
Monitoring, model updates, and performance tuning by our Malaysian team — with enterprise response-time commitments.
Industries
Built for industries where data can't leave
Banking and financial services
Customer data and risk models that must stay onshore
Healthcare
Patient records analysed without leaving your network
Government-linked organisations
Sovereignty requirements met with air-gapped options
Manufacturing
Process knowledge and IP kept inside the plant
FAQ
Questions your CTO will ask
Not with a private deployment. We install open-weight models on your own servers — on-premise or in your private cloud — so prompts, documents, and outputs stay inside your network. Air-gapped deployment is available for the strictest environments. If a workload uses Claude instead, it runs through enterprise API agreements where your data is not used for model training by default.
It depends on what your regulators and policies allow. Private open-weight models (Llama, Qwen) give you full data sovereignty — nothing leaves your servers. Claude offers frontier capability through enterprise API and cloud-platform agreements with enterprise controls. Many clients run a hybrid: private models for sensitive data, Claude where policy permits. As a member of the Anthropic Claude Partner Network that also builds private deployments, we advise on the mix without bias toward either.
A private LLM assistant with RAG on your documents typically goes live in 6-12 weeks, including hardware sizing, model selection, and security review. Smaller pilots can run inside 4 weeks. We start with an assessment that gives you a concrete timeline and infrastructure plan before any commitment.
Yes — that is most of the work. We integrate with your SSO and directory services for access control, connect to existing document stores and databases for retrieval, and expose the assistant through APIs your internal systems already speak. If you need GPU hardware, we supply and install certified servers through our hardware partners.
Our Malaysian team provides ongoing managed support: monitoring, model updates, performance tuning, and user onboarding — with response-time commitments for enterprise agreements. You are not left running unfamiliar AI infrastructure alone.
Start a conversation
Ready to run AI on your own terms?
A private AI assessment maps your use cases, infrastructure, and compliance constraints to a concrete deployment plan — with timeline and hardware sizing. No obligation, and your data stays exactly where it is.